Monitoring, des outils pour superviser nos infrastructures et applications

Les infrastructures et environnements applicatifs deviennent toujours plus complexes. Cela demande de pouvoir garder un oeil sur le tout et de s’assurer de pouvoir aisément automatiser les réactions, en cas de défaillances. Nous allons tenter d’aborder dans cet article quelques solutions qui permettent d’apporter cette vision globale sur tous nos éléments, que cela soit physique ou cloud. Revue des produits à la mode.
Un oeil….sur tout !
Le monitoring ou supervision d’infrastructures consiste à pouvoir contrôler le bon fonctionnement des solutions informatiques d’un environnement d’entreprise ou d’exploitation. Pour effectuer ce genre de surveillance, il existe des standards dans le monde informatique (aussi bien dans les protocoles réseaux qu’au sein des systèmes d’exploitations). Ces standards vont nous permettre de collecter des données d’utilisation en temps réel et de pouvoir permettre de notifier aux administrateurs sur l’état général. Par la suite, on va établir des règles automatiques, pour régler des problèmes connus ou récurrents, afin de faciliter le travail de gestion centralisé.

Il faut tout d’abord comprendre comment les actions de supervision se définissent sur les éléments sources (c’est-à-dire sur des machines ou des applications). Chaque élément à contrôler dispose d’un accès par le biais d’un protocole (exemple SNMP ou WMI) et avec une gestion d’identité, avec des droits d’administration (ou également appelé profil d’administration). Par exemple, le SNMP permet par le biais d’une définition d’échange soit de lire un état, soit d’interagir avec l’objet que l’on supervise.
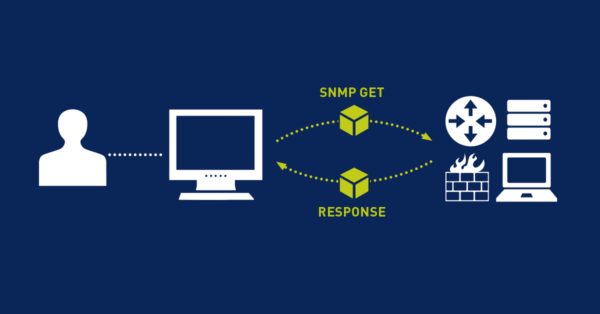
Il faut voir dans ces protocoles réseaux, dédiés au monitoring, des moyens d’accès à l’information sur l’état de fonctionnement. Par exemple, si une machine n’est plus présente sur le réseau (ou considérée comme éteinte), on va essayer de tester sa présence (PING et réponse ICMP), et selon le résultat, on va signifier la situation à l’administrateur de l’environnement. On peut aussi interroger Windows, par le biais de WMI et lui demander, avec le bon utilisateur et les droits nécessaires, de nous dire si telle application ou tel service fonctionne ou est stoppé. Toutes ces situations peuvent s’appliquer et se vérifier, par différents moyens (protocoles) ou avec l’installation d’agents (des mini-programmes de contrôle spécifique), qui vont relayer soit en temps réel, soit à des moments programmés.
Les outils existants sont nombreux dans le domaine. Il existe divers sites qui recensent ces outils, comme par exemple: https://www.monitoring-fr.org Commençons par une série d’outils. Le premier est PRTG. La société Paessler, qui propose cette solution, a développé une plateforme de supervision, fonctionnant sous Windows. Il est possible, via les protocoles standards d’administration, de gérer aussi bien des composants physiques et des applications de toutes sortes.
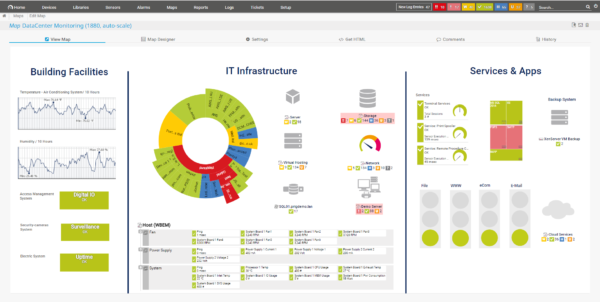
Dans la même tendance sous serveur Windows, il y également la solution de ManageEngine OpManager. Le produit se décline dans diverses versions (gratuite pour le module de base et des versions payantes pour un support étendu, avec des fonctions supplémentaires).
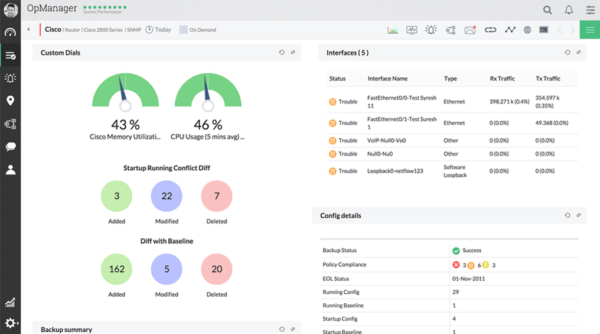
Egalement très populaire, les solutions SolarWinds proposent une gestion de la supervision très poussée, avec des interfaces riches en indications.
Vidéo d’introduction (en anglais):
L’inconvénient principal de ces solutions réside dans le fait qu’il faut dédier un serveur Windows, pour la tâche de supervision (ce qui peut être considéré comme une solution lourde, selon les environnements). Ce qui nous amène à employer ou envisager des produits, pouvant fonctionner dans des systèmes de containérisations.
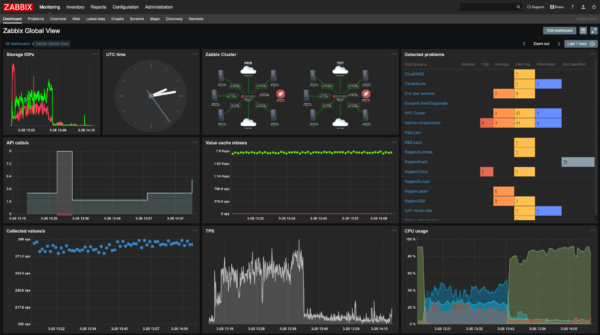
Passons à une solution pouvant fonctionner sous Linux: voici Zabbix, une administration en mode Web, pouvant effectuer des analyses réseaux pour découvrir les éléments à superviser, avec également la possibilité de se connecter à des API pour analyser le fonctionnement des applications (on premise ou en SaaS). Voici une vidéo sur la mise en place dans un LXC:
Comme vous pouvez le constater, la mise en route initiale peut se réaliser très rapidement et permet une gestion centralisée des solutions.
Il existe un grand nombre de possibilités dans le monde de l’Open Source. pour en citer certains: Nagios, NetData (ces deux-là sont basés sur du Linux et peuvent fonctionner en container, comme Zabbix). Il y a aussi ZenOss, ou encore Centreon, qui se décline avec des offres commerciales.
Le travail de configuration est plus conséquent, selon la complexité de l’infrastructure à superviser ou les règles de gestion que vous souhaitez mettre en place. Il est recommandé de planifier et d’établir les notions de gestion avant de choisir l’outil approprié et de se lancer dans sa mise en route.
Il se peut également que dans certains cas, il soit nécessaire d’utiliser plusieurs outils de supervision, pour gérer tous les cas opérationnels. Et cela peut parfois entraîner une perte de maîtrise de l’ensemble. Il faut à ce moment-là, s’appuyer sur ce que l’on appelle des aggrégateurs d’informations pour la supervision.
C’est la mission d’une solution comme Grafana.
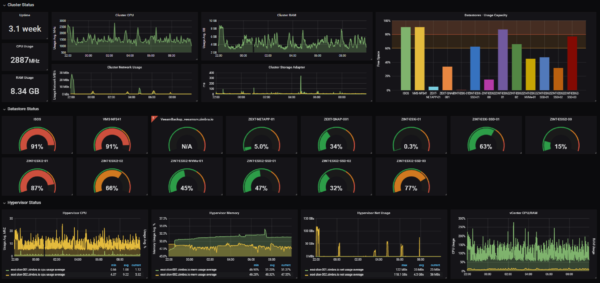
Permettant de gérer diverses sources de données simultanément, de les analyser et de créer des panneaux de contrôles (Dashboards) enrichis, Grafana permet également d’automatiser les processus de résolutions de panne ou de faire la notification avancée pour les administrateurs. Voici la vidéo de leur conférence en 2019, qui montre l’usage de la console et la création de Dashboards dans Grafana:
En résumé…c’est contrôlé ?
Comme vous avez pu le constater, le nombre de produits existants est assez conséquent. La difficulté, pour s’y retrouver dans la jungle des offres de solutions, c’est d’avoir une idée bien précise de ce que l’on a à superviser, du temps que l’on peut y consacrer et de comment nous souhaitons automatiser les processus de récupération, en cas de défaillance de nos systèmes. On appelle cela un plan de désastre ou DRP (Disaster Recovery Plan). Il est important de s’appuyer sur les outils de supervision, pour gagner en réactivité et permettre une identification rapide des problèmes. L’analyse du besoin requiert de s’appuyer sur des professionnels du métier, qui sauront comprendre, analyser votre situation et proposer les bonnes alternatives.
